一、前言
当涉及手写数字识别时,我们通常指的是将手写数字的图像作为输入,然后使用机器学习或深度学习模型对这些图像进行分类,以确定它们代表的数字是什么。手写数字识别在许多现实世界的应用中都具有重要意义,比如邮政编码识别、支票处理、自动化填写表格等。此外,随着智能手机和平板电脑的普及,手写数字输入也成为了用户与设备交互的一种方式,因此手写数字识别模型在移动设备上也有着重要的应用前景。
在本文中,我们将探讨如何使用深度学习技术来构建一个手写数字识别模型。我们将介绍如何准备数据、构建神经网络模型、训练模型,并最终评估模型的性能。我们将着重介绍如何使用 TensorFlow 和 Keras 这两个流行的深度学习框架来实现这一目标。
二、MNIST数据集简介
当我们学习新的编程语言时,通常第一个程序就是打印输出著名的“Hello World!”。在深度学习中,MNIST数据集就相当于Hello World。MNIST是一个简单的计算机视觉数据集,它包含手写数字的图像集:
数据集:
- train-images-idx3-ubyte 训练数据图像 (60,000)
- train-labels-idx1-ubyte 训练数据label
- t10k-images-idx3-ubyte 测试数据图像 (10,000)
- t10k-labels-idx1-ubyte 测试数据label
每张图像是28 * 28像素:
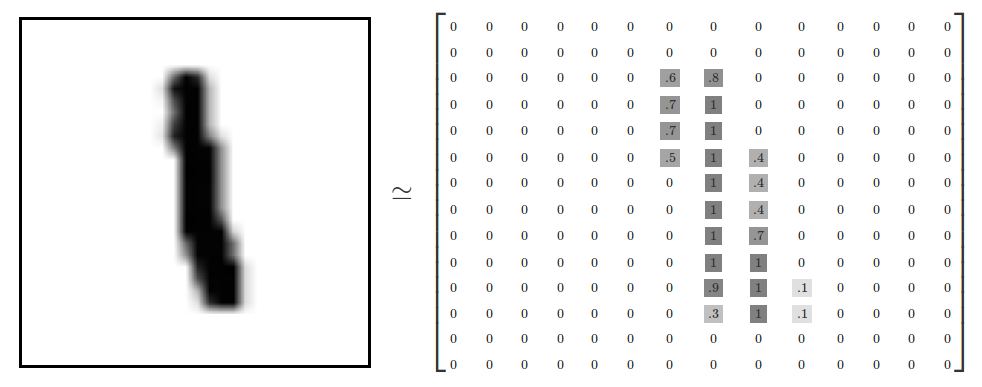
我们的任务是使用上面数据训练一个可以准确识别手写数字的神经网络模型。
三、手写数字识别
1、准备工作
(1)首先是导入需要使用的包:
import gradio as gr |
(2)加载MNIST数据集,它实际上是在获取一个广泛用于测试机器学习算法性能的标准数据集。MNIST数据集包含了大量手写数字图像,每个图像都是28x28像素的灰度图像。对于每个图像,都有一个相应的标签,表示图像中所显示的数字。
mnist = keras.datasets.mnist |
keras.datasets.mnist是TensorFlow中内置的数据集之一。调用mnist.load_data()会自动下载MNIST数据集(如果它尚未在本地缓存中),并将数据集分为训练集和测试集。训练集包含60000个样本,而测试集包含10000个样本。
train_images和test_images是图像数据,它们是NumPy数组,每个元素都是一个28x28的矩阵,表示一个手写数字图像。train_labels和test_labels是与图像对应的标签,它们是整数数组,每个元素表示相应图像中所显示的数字。
2、数据预处理
数据预处理是为了确保输入数据适合用于训练卷积神经网络模型。
Reshape(改变形状):
- 原始的MNIST图像数据是一个3维的数组(60000, 28, 28),表示60000张28x28像素的灰度图像。
- 为了适应卷积神经网络的输入要求,我们需要将图像的形状改变为4维数组(样本数量,图像高度,图像宽度,通道数)。
- 这里使用
reshape函数将训练集和测试集的图像数据从(60000, 28, 28)和(10000, 28, 28)reshape为(60000, 28, 28, 1)和(10000, 28, 28, 1),表示每个图像是28x28的灰度图像,通道数为1。
归一化(Normalization):
- 归一化是将图像数据的像素值缩放到0到1之间的过程,以便更好地用于训练神经网络模型。
- 在这个示例中,对图像数据进行了归一化处理,将像素值除以255.0,将像素值范围从0到255缩放到0到1之间。
标签处理:
- 原始的标签数据是整数数组,每个元素表示相应图像中所显示的数字。
- 为了用于训练神经网络模型,通常需要进行one-hot编码,将每个整数标签转换为一个长度为类别数量的向量,其中对应标签的位置为1,其他位置为0。
- 使用
keras.utils.to_categorical将训练集和测试集的标签进行了one-hot编码,将整数标签转换为长度为10的向量,因为MNIST数据集共有10个类别(0到9)。
3、构建CNN模型
我们使用了 TensorFlow 和 Keras 来构建 CNN 模型。
model = keras.Sequential([ |
keras.Sequential([]): 这是 Keras 中用于构建序列模型的方法。它允许我们按顺序堆叠各种神经网络层。keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)): 这是一个卷积层,用于提取图像特征。其中的参数含义如下:32: 这表示卷积核的数量,也就是输出的特征图的深度。(3, 3): 这是卷积核的大小。activation='relu': 这表示使用 ReLU 激活函数。input_shape=(28, 28, 1): 这是输入图像的形状,表示为 (height, width, channels)。在这里,输入图像的大小是 28x28,通道数为 1(因为这是灰度图像)。
keras.layers.MaxPooling2D((2, 2)): 这是池化层,用于对特征图进行下采样,以减少参数数量并提取最显著的特征。接下来的两个部分是类似的卷积层和池化层,用于进一步提取和压缩特征。
keras.layers.Flatten(): 这一层用于将多维的特征图展开成一维,以便连接全连接层。keras.layers.Dense(64, activation='relu'): 这是一个全连接层,包含 64 个神经元,并使用 ReLU 激活函数。keras.layers.Dense(10, activation='softmax'): 这是输出层,包含 10 个神经元,对应于数据集中的 10 个类别(数字 0 到 9),并使用 softmax 激活函数输出分类概率。
4、编译模型
我们使用 Adam 优化器、分类交叉熵损失函数和准确率作为评估指标。
# 编译模型 |
在这段代码中,compile 方法用于编译神经网络模型。传递给 compile 方法的参数包括:
优化器(optimizer):在这里,我们使用了 Adam 优化器。Adam 是一种常用的随机梯度下降优化算法,它结合了 AdaGrad 和 RMSProp 的优点,并添加了偏差修正。
损失函数(loss):对于分类任务,我们通常使用交叉熵损失函数。在这个例子中,我们使用了
categorical_crossentropy,它适用于多类别分类问题。评估指标(metrics):在训练过程中,我们通常需要监控模型的性能。在这里,我们使用了
accuracy作为评估指标,以便在每个训练周期(epoch)结束后输出模型在训练集和测试集上的准确率。
这样,编译模型的过程就完成了。一旦模型被编译,它就可以被用于训练(通过 fit 方法)、评估(通过 evaluate 方法)和预测(通过 predict 方法)。
5、模型训练
这部分代码是用于训练神经网络模型的关键部分。
model.fit(train_images, train_labels, epochs=5, batch_size=64, validation_data=(test_images, test_labels)) |
model.fit: 这是 Keras 模型中用于训练模型的方法。它接受训练数据、标签数据以及一些训练的参数。
train_images, train_labels: 这是用于训练的图像数据和对应的标签。epochs=1: 这指定了训练的轮数,即模型将对整个训练数据集进行一次完整的迭代。在这里,模型仅进行了一次迭代(一个epoch)。batch_size=64: 这指定了每个训练批次的大小。在每个epoch中,训练数据将被分成多个小批次,每个批次包含的样本数为64。validation_data=(test_images, test_labels): 这是用于在训练过程中验证模型性能的数据。在每个epoch结束时,模型将在这些验证数据上进行性能评估。
当你调用model.fit方法时,模型将根据训练数据和标签进行训练,并且在每个epoch结束时,它会计算并输出一些指标,比如损失值和准确率。
6、创建预测函数
我们需要对输入的图像进行预处理,并使用预训练的模型对图像进行分类预测。
def classify_image_with_loaded_model(img): |
在进行预测之前,需要将图像的维度扩展一个维度,因为模型期望的输入维度为 (batch_size, height, width, channels),这里我们的 batch_size 为 1,因此使用 np.expand_dims 将图像的维度从 (28, 28, 1) 扩展到 (1, 28, 28, 1)
在这个函数中,我们首先将输入的图像转换为 NumPy 数组,并将其转换为灰度图像。然后,我们调整图像尺寸为模型期望的大小(28x28),并对图像的像素值进行归一化处理。接下来,我们使用预训练的模型对处理后的图像进行分类预测,并将预测结果以字典的形式返回,其中键为类别标签,值为预测概率。
这个预测函数将会被 Gradio 库用于创建一个交互式界面,使用户能够上传手写数字图像,并通过模型进行实时的分类预测。
四、运行程序
运行整个程序,在控制台中可以看到输出
accuracy: 0.9448 - val_loss: 0.0550 - val_accuracy: 0.9827 |
可以看到随着循环次数的增加,模型识别的准确度也在增加。
在演示空间中运行有

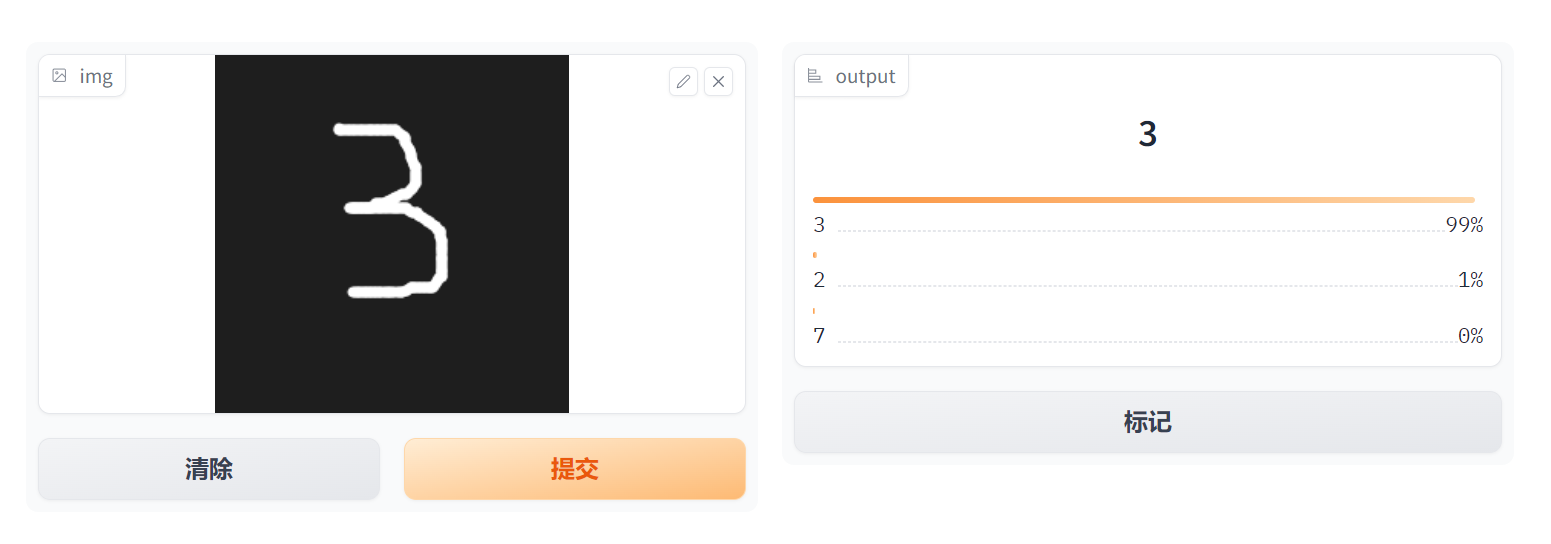
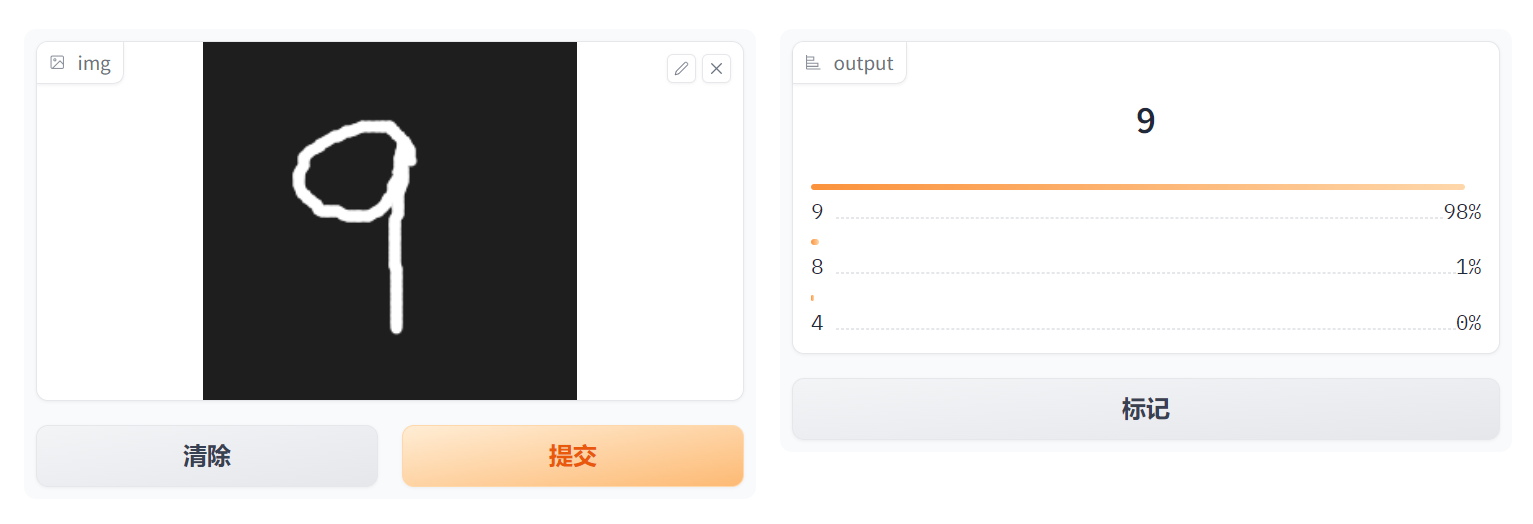
五、优化
用训练好的模型来识别手写图片的时候,发现图片为黑底白字时识别率显著较高,而其他底色的图片识别率很低,应该是Minst数据集都是黑底白字的图片导致的。所以为了提高准确性,对训练模型用的数据图片加强了一下,同时增加类别权重,现在准确度提高了很多。
# 数据增强 |
这里9的权重是2的原因是手写的9容易和4混淆。
# 类别加权 |